👉EXAMPLE: CUSTOMER EXPERIENCE INSIGHTS
Every company has it – customer feedback like an NPS rating or stars on Amazon. Then most ask an open-ended question why. That’s all that you need.
First, make sure to categorize feedback into the topics mentioned as granular as possible. NLP deep learning systems can help to scale this.
Causal Machine Learning can unfold its magic. The categorized feedback comes as binary variables. Text AI also produces sentiment information that measures the totality of language. Also, context information can serve as additional predictors.
Causal Machine Learning can take care of so-called intermediary variables too. Besides the sentiment, a category like “great service” is such an intermediary variable as it is driven by more specific ones like “friendliness”.
The model then can find out that friendliness is the key behind “great service”. A conventional driver analysis would have totally missed the importance of friendliness because categories are not independent.
On average, Causal Machine Learning doubles the explanatory power of conventional driver analysis. This means it reduces the risks of wrong decisions by 50%.
The cx-ai.com is a solution that leverages Causal Machine Learning, provides CX and fiscal impact predictions as well as an ROI decision-making framework
👉 EXAMPLE: CREATIVE INSIGHTS
To understand how a commercial will succeed, it is not enough to measure how well it performs (this is the focus of copytesting today). Instead, you also need to measure what it does.
In a large syndicated study, we annotated (categorized) over 600 spots of 6 product categorize to describe what the TV spots actually are doing.
Do they use a spokesperson? Do they use a problem-solution framework? Does it use a song that corresponds to the acting message? We coded the technical properties of a spot.
Then we coded the emotional message each spot was making. Each spot can be categorized into one of the dozens of topics like “it tastes good”, “it can be trusted”, “good for the family”, etc.
This data is then merged with copy testing data. With this data, Causa Machine Learning can now understand which tactics and which emotional messages work in your category.
We called the approach Causal.AI. It can not invent an actual creative conception. But it gives clear guiding rails about which strategies will work and which don’t.
👉 EXAMPLE: NEW PRODUCT INSIGHTS
When launching a new product, much can go wrong. Distribution, brand, packaging, promotion, first product experience, pricing – all this needs to be good enough. It’s a success chain at which the weakest link determines winning or losing.
Each step on its own as well as all together is an application for causal machine learning.
Before this, typically, you want to test a product concept and learn WHY it is not crushing the crowd.
Test the concept with implicit response measure and then get feedback on the classical eight dimensions of product adoption. It will tell you what consumers think about the product but not (yet) why they don’t buy it.
It takes a causal machine learning model to measure how important those dimensions are.
We ran the process for a new speaker concept. We learned the most crucial thing for marketers to look at was communicating why it was different from (uniqueness dimension) than the competition.
Each product has its topics. It could be ease of use, appeal, utility, certainty, trust, or compatibility with the consumers’ lives.
Applying USM (causal machine learning) is essential to translate data into predictive insights that work.
👉EXAMPLE PRICING
Price.AI is a methodology that lends methods from psychology to measure unconscious attitudes in lightspeed.
It tricks conscious minds by measuring reaction time on whether or not the shown price is fair or risky or attractive or with “want to buy” and so forth. AI then is trained to predict the willingness to buy.
This AI helps to consider the attribute’s nonlinear link to purchase and lowers the required sample size.
In the end, the method delivers an accurate price demand function. It can be retrieved in an automated process with as low as 50 respondents. As such, pricing becomes not only precise but also scalable.
👉 EXAMPLE: SALES, MARKETING, MEDIA MIX MODELING
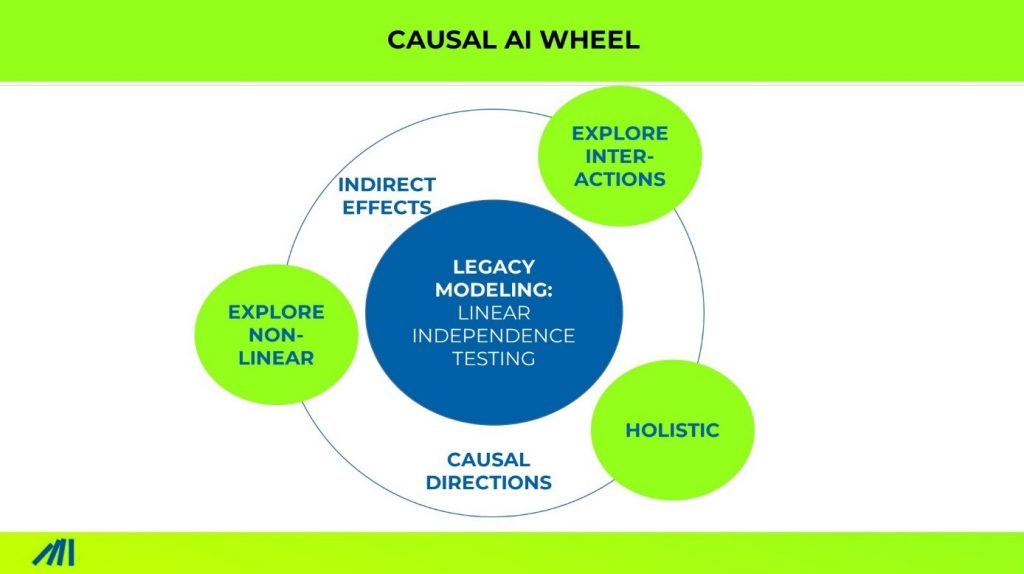
A MMM model based on causal machine learning solves all problems mentioned above.
It automatically models channel interactions and nonlinear effects, especially those nobody is aware of.
Most importantly, it considers the indirect effect. The brand-building effect is an indirect causal effect. Any MMM model should include indicators of brand strength.
It also considers the biggest context and confounding factor: the creative quality. There is no ad impact if the ad is bad, no matter how much money you pour into the channel.
You don’t have data for that? If you do copy testing you do. Nowadays, you can even buy such information or teach a deep-learning AI that can predict it.
This are 5 questions you should challenge your MMM vendor with:
https://www.success-drivers.com/what-can-marketing-mix-modelling-provide/
👉 EXAMPLE: Price promotion effect
Understanding the impact of price promotion is a natural outcome of a holistic sales model.
Causal machine learning enables holistic models with ease by adding predictive power at the same time.
Conceptually, sales must be modeled as an outcome of the price at the time (=price effect), the price of the past (=early purchase effect), the price of the future (=promotion anticipation effect), and all other circumstances.
If the price of the future or the past predicts sales of today, we have the prove that purchases just shifted due to pricing)
👉 EXAMPLE: BRAND POSITIONING INSIGHTS
Brand positioning is a vast field. Depending on the approach, you may actually measure different things.
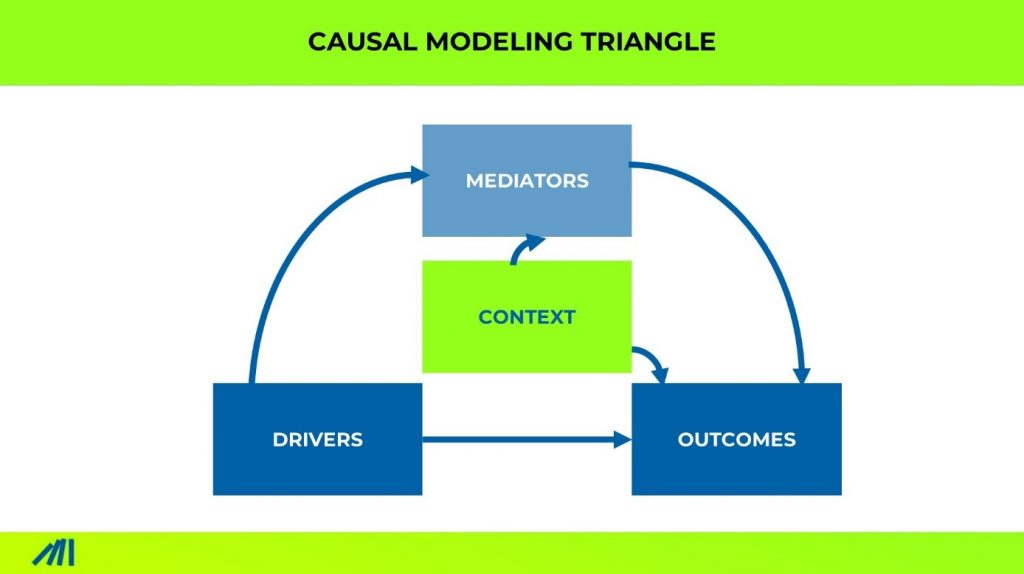
No matter what you are measuring, these data can be grouped into final outcomes (e.g., purchase intention), intermediate outcomes (e.g., consideration, awareness, liking, etc.), drivers (image items, features, feature perceptions, etc.), and context (demographics, product usage, psychography, etc.).
The causal directions between variables are known for 95% of the paths based on marketing science. Causal direction tests can test the rest. This structure guides the model building.
Causal Machine Learning then does the legwork.
The whole details of the T-Mobile case can be found here.










 ).
). 




{kind=link}