Founder of CX-AI.com and CEO of Success Drivers // Pioneering Causal AI for Insights since 2001 // Author, Speaker, Father of two, a huge Metallica fan.
Author: Frank Buckler, Ph.D. Published on: May 18, 2021 * 9 min read
If you receive huge amounts of unstructured data in the form of text (emails, social media conversations, chats), you’re probably aware of the challenges that come with analyzing this data.
Manually processing and organizing text data take time, it’s tedious, inaccurate, and it can be expensive if you need to hire extra staff to sort out text.
Nowadays, in 2021, we all need to know more about what data analysis methods we have been using for a long time and why it is more important than ever to perform text analysis using AI tools in order to automatically analyze the text in real-time.
Let me give you some guidance on this below…
Get your FREE hardcopy of the “CX Insights Manifesto”
FREE for all client-side Insights professionals. We ship your hardcopy to USA, CA, UK, GER, FR, IT, and ESP.
Manual Coding vs Unsupervised Cateogization vs Supervised Categorization
There are three methods of categorization:
Manual coding – manual categorization is when human sits down, looks at verbatims (text response) and categorizes points in the buckets.
Unsupervised categorization means using unsupervised natural language processing, unsupervised AI, or whatever you may call it… It’s a method where you upload your text and it does a bunch of magics without even you knowing about it and in the end, it gives you categories.
Supervised categorization, supervised texts, whatever you call it. It is called supervised because human teaches the system (AI) to categorize.
You need to bear in mind that each of them have pros and cons and let’s discuss them.
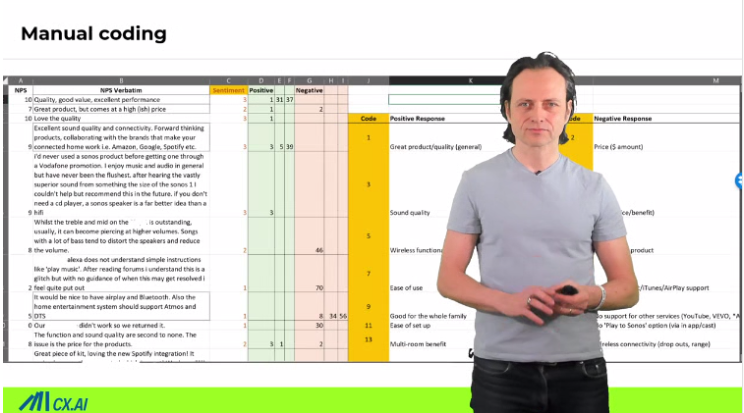
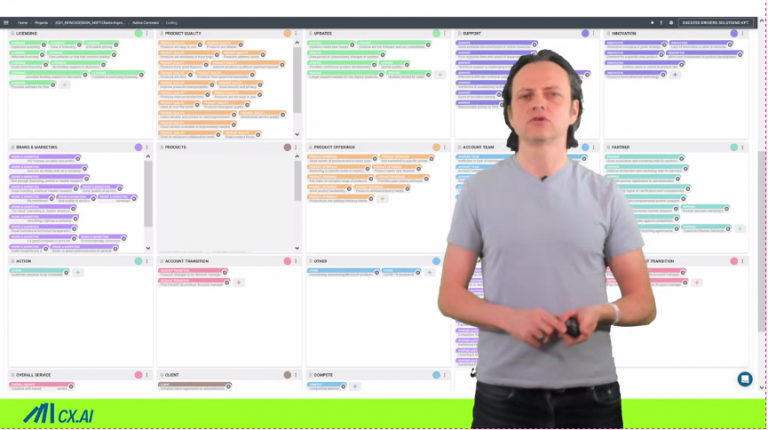
That’s how typical menu coding looks like. You have all your verbatims. You may even have NPS score next to it. And when you start off, you will start to develop codebooks. This means there are different categories where the verbatims may belong to. Once you start coding, you add one or another category to it.
This example differentiates between positive and negative categorization. Every code gets a code number, and that’s how it works. And really it’s a piece of excel. You have some rules because customers talk not just about one topic but about many topics. you may have several columns and the coder goes through it and for the most frequently used topics they know the codes in their mind.
Quality is always around 10 and then they type it in it’s super fast for them. One say, have a look in the codebook and that’s how it goes. They go through all your hundreds of thousands or 10 thousands of verbatims, one by one and try to categorize it. That’s the process. And what some also do is trying to judge on the sentiment. We will talk about it in more detail later.
In this case sentiment means how emotional this response is or is it super emotional? Is it just positive? That’s also what you can do. Human coding it, and once you have coded that, then you can start counting. How many people are saying price is too high? That’s my new coding. And of course there are lots of do’s and don’ts, which we’ll discuss in a bit.
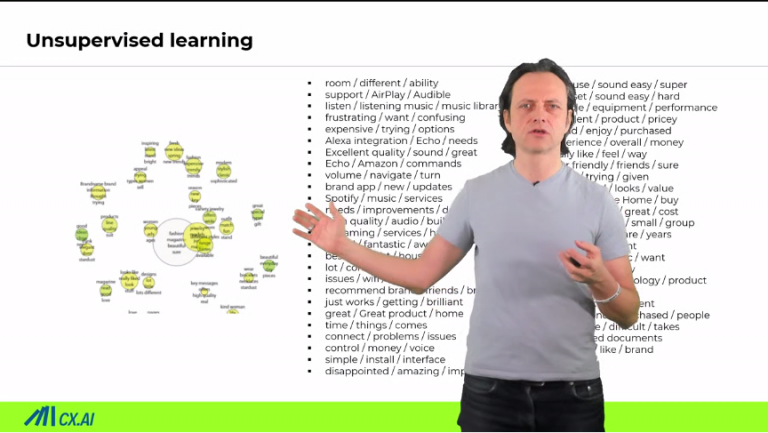
Second unsupervised learning, unsupervised AI, unsupervised text analytics. It’s again, you just take your day, upload it and just by magic, it comes up with a bunch of clusters. It comes up with a bunch of different categories.
basically clusters, verbatims, or pieces within verbatims to each other, which sound kind of similar. There are of course different techniques to do that. But what you get is just an example of what you get. Then of course there are differences between the technology. But what you see, it seems to generally make sense but not always.
You have, you have still some parameters where you can say, give me just 10 categories. Don’t be so specific or vice versa, but there is no way that you teach the system, because otherwise it would be a supervised learning system.
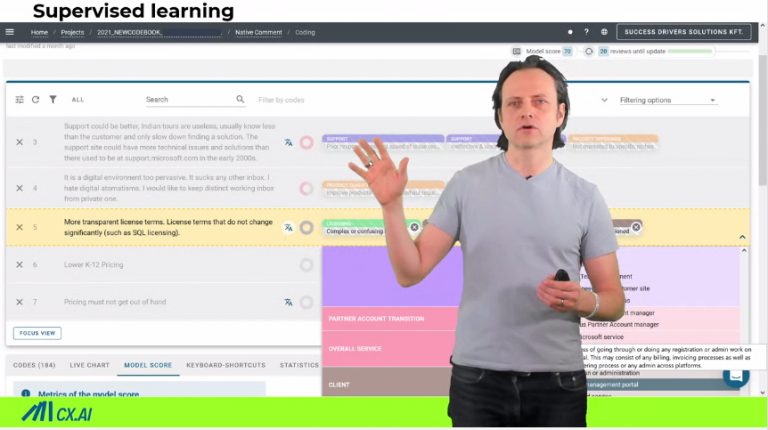
Below you can find an example of a supervised learning system. the verbatims, and then you start coding here in the software, put some numbers… it’s like manual coding, right? You have a dropdown menu and you can pick and choose.
This is especially good when you have large code books and it’s really hard to remember those numbers. You can be quite fast with software help, and also, it helps you to manage descriptions. Sometimes it’s not enough to just read the label of a categorization you would like to learn in more detail. What is really meant by this categorization and the software also gives you a validity score on how precise the model learned is, because you start teaching the system, but after a few hundred examples, it will pretty much be as good as you, it can categorize the rest for the time being, or even for the future.
The beauty here is that in contrast to manual coding where you start with the list that has a random order… When you start coding it, there are some topics which pop up frequently.
Every second verbatim reads quite similar. It takes a lot of time to eventually get to topic, which is rare. And this is different with supervised learning because supervised learning can help you to detect what’s seldom in the data. If it is already good at understanding the quality, it will not show you quality anymore.
When it’s already been mentioned it shows you something different, you will be much faster in teaching this AI to understand to categorize everything.
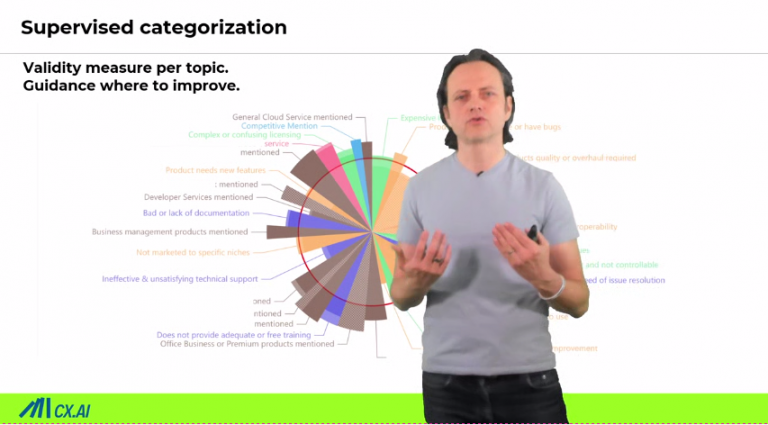
Another example (also advantage) of this system is that it’s much better to manage huge codebook. Below you seen an example of 150 codes, and actually this is hard to bear in mind but with this software it’s much better because you can quickly find the codes and again and again read the definitions.
So then, it is easier to become consistent. Also, the system can help you to really understand where you need to become better because this is this, I example, coats. Where the thick slices, they are often mentioned like this. But if it’s below the circle, the validity is not so good.
this is very important to work on. There are others topics, which, where you’re also not very good at, but they are very seldom. you can read and look at where, which codes are already trained. Well. And then try to find you once or revisit what you have coded. it just gives you guidance to detect your own errors, which is not possible in menu coding.
Keep Yourself Updated
On the Latest Indepth Thought-Leadership Articles From Frank Buckler
There are three types of categorization, manual, unsupervised, and supervised categorizations. There are some dos and don’ts for categorizations and building the definitions of the categories, especially also for the label convention. It’s important to build granular code books to label it very specifically and to avoid other categories.




{kind=link}