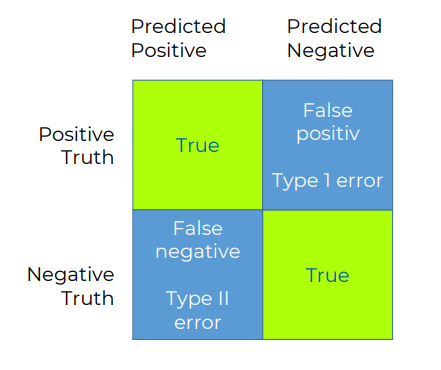
Here,
- True positive indicates the outcome where the model correctly predicts the positive class.
- True Negative indicates the outcome where the model correctly predicts the negative class.
- False positive indicates the outcome where the model incorrectly predicts the positive class.
- False negative indicates the outcome where the model incorrectly predicts the negative class.
As evident from the above grid, false positive is the type one error, and false negative is the type two error.
Alpha vs. Beta Failure – Alpha failure is also called False Positive, Type 1 error, or Producers’ risk. If the alpha failure is 5%, it means there is a 5% chance that a quantity has been determined defective when it actually is not.
On the other hand, Beta failure is also called False Negative, Type 2 error, or Consumers’ risk. It is the risk that the decision will be made that the quantity is not defective when it really is.
F1 score – It is the ultimate measure of consistency that takes both false positives and false negatives into account. It takes everything, weights it, measures its frequency, and comes up with the right measurements. So, F1 score is the gold standard score used in science to measure categorization quality.
But, F1 score only measures what you are doing is consistent or not. You are not sure if it’s correct. So, there is another term when we talk about validity, and that is Predictive Power.
Predictive Power – It is the measure of truth that helps you find the true categorization. The truth can be best found by determining whether or not it is useful to predict the outcomes. If you have something that is described through the category, and it has an impact in the world, we categorize it. It’s because we think it is important to drive outcomes. So, if this can predict outcomes because it was some kind of important, then it’s probably correct.
In short, predictive power is the test to measure true categorization, and to predict and measure outcomes. So, the R2 of everything you do towards outcomes is the final measurement of whether or not your categorization is great.





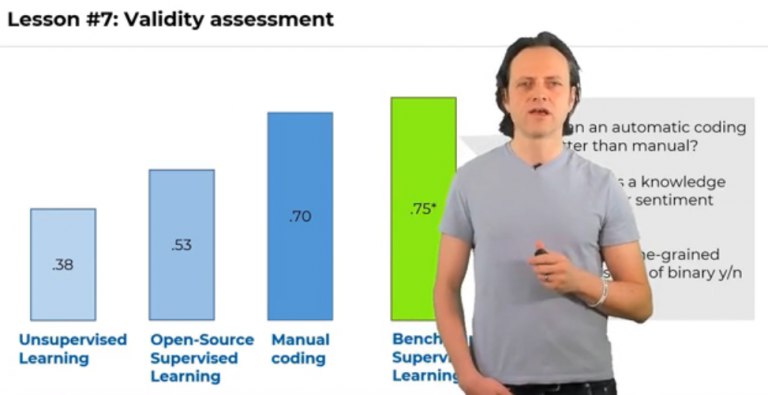

{kind=link}